
[Section2] 03. 자료구조와 알고리즘 - Stack과 Queue / 20230512
🧑🏻💻 TIL(Today I Learned)
✔️ 자료구조, 스택, 큐
1. 자료 구조(Data Structure)
➡️ 여러 데이터의 묶음을 저장하고 사용하는 방법을 정의한 것
➡️ 데이터를 효율적으로 다룰 수 있는 방법을 모아 자료 구조라는 이름을 붙인 것
📍 데이터(Data)란?
: 문자, 숫자, 소리, 그림, 영상 등 실생활을 구성하고 있는 모든 값, 하지만 그 자체만으로는 정보를 가진다고 하기 힘듦
→ 나이라는 데이터만 알고 있다면 사람의 나이인지, 동물의 나이인지, 나무의 나이인지 누구의 나이인지 알 수 없음
즉 데이터는 분석하고 정리하여 활용해야 의미를 가질 수 있음!
→ 사용 목적에 따라 형태를 구분하고 분류하여 사용해야 한다는 의미
→ 물건을 정리하면 쉽게 찾아 쓸 수 있듯이 데이터를 체계적으로 정리하여 저장해 두는 것이 데이터를 활용하는 데 있어 훨씩 유리함
➡️ 많은 자료 구조를 알아두면 어떠한 상황이 닥쳤을 때 적합한 자료구조를 빠르고 정확하게 적용하여 문제를 해결할 수 있음
(상황에 적합하고 정확한 코드 작성에 유리)
2. Stack(스택)
➡️ 쌓다, 쌓이다 와 같은 뜻을 가짐
➡️ 접시를 쌓아 놓은 형태와 비슷한 자료 구조 즉, 데이터를 순서대로 쌓는 구조
🔎 특징
1. LIFO(Last In First Out)
➡️ 먼저 들어간 데이터는 제일 나중에 나오는 후입선출의 구조
// 1, 2, 3, 4를 스택에 차례대로 넣음
Stack<Integer> stack = new Stack<>(); //Integer형 스택 선언
stack.push(1);
stack.push(2);
stack.push(3);
stack.push(4);
---------------------------
1 <- 2 <- 3 <- 4
---------------------------
// 들어간 순서대로, 1번이 제일 먼저 들어가고 4번이 마지막으로 들어가게 됨
예2) 스택이 빌 때까지 데이터를 전부 빼냅니다.
stack.pop();
stack.pop();
stack.pop();
stack.pop();
---------------------------
---------------------------
4, 3, 2, 1
// 제일 마지막에 있는 데이터부터 차례대로 나오게 됨
//스택이 비어 있는지 확인할 때는 empty 연산을 사용
stack.empty(); // true 반환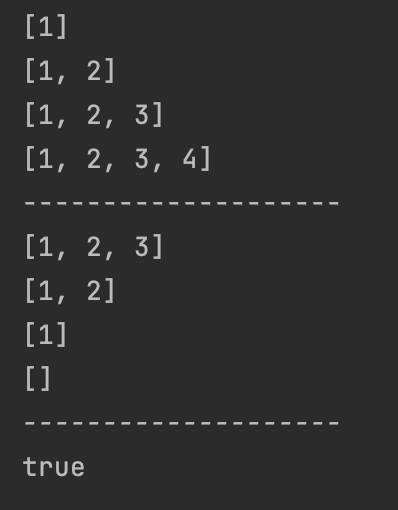
➡️ 실제로 출력해 보면 이렇게 들어오고 나오는 과정을 확인할 수 있음
2. 데이터는 하나씩 넣고 뺄 수 있음
: 데이터가 아무리 많이 있어도 하나씩 데이터를 넣고 뺌, 한꺼번에 여러 개를 넣거나 뺄 수 없음
3. 하나의 입출력 방향을 가지고 있음
: 데이터의 입출력 방향이 같음, 입출력 방향이 여러 개라면 Stack 자료 구조라고 볼 수 없음
✍🏻 장점
- 스택은 후입선출(LIFO) 구조를 가지기 때문에 스택에 저장된 데이터를 가져오는 속도가 매우 빠름
: 데이터의 삽입과 삭제가 스택의 맨 위에서 이루어짐, 즉 다른 데이터의 위치를 변경할 필요 없음
데이터를 삽입, 삭제할 때 모든 데이터를 순회할 필요가 없기 때문에 스택의 크기와는 상관없이 항상 매우 빠르게 처리됨 - 자바에서는 스택을 기본 자료 구조로 제공하기 때문에 별도의 라이브러리나 모듈을 설치할 필요 없음
: 따로 스택을 구현하지 않아도 Stack 클래스가 구현되어 있음
✍🏻 단점
- 크기 제한이 없음
: 데이터를 저장할 때 크기가 제한되지 않기 때문에 메모리 사용량이 불필요하게 증가할 수 있음
그래서 스택의 크기를 미리 정해놓거나, 동적으로 크기를 조절하는 방법을 사용해야 함 - Stack 클래스는 Vector 클래스를 상속받아 구현되어 있어 크기를 동적으로 조정하지 않음(Java에서 제공하는 것 한정)
: Vector 클래스는 내부적으로 배열을 사용하여 구현되어 있음 이 배열의 크기는 처음에 지정된 크기만큼만 할당되고 스택에 저장되는 데이터 개수가 배열의 크기를 초과하면 새로운 배열을 할당하고 기존 데이터를 새로운 배열로 복사하는 작업 수행 - Stack 클래스는 Vector 클래스를 상속받아 구현되어 있어 데이터를 삽입, 삭제할 수 있게 됨 (Java에서 제공하는 것 한정)
: Stack 클래스는 Vector 클래스를 상속받아 구현되었기 때문에 Vector 클래스의 모든 메서드 사용 가능
3. Queue(큐)
➡️ 줄을 서서 기다리다, 대기행렬이라는 뜻
톨게이트를 예로 들면 가장 먼저 진입한 자동차가 가장 먼저 톨게이트를 지남
즉, 가장 나중에 진입한 자동차는 먼저 도착한 자동차가 모두 빠져나가기 전까지는 톨게이트를 빠져나갈 수 없음
➡️ FIFO(First In First Out) or LILO(Last In Last Ount) : 먼저 들어간 데이터가 먼저 나옴
➡️ 큐에 데이터를 넣는 것을 enqueue, 큐에서 데이터를 꺼내는 것을 dequeue
➡️ 데이터가 입력된 순서대로 처리할 때 주로 사용
🔎 특징
1. FIFO(First In First Out)
➡️ 먼저 들어간 데이터가 제일 처음에 나오는 선입선출의 구조
// 1, 2, 3, 4를 큐에 차례대로 넣음
Queue<Integer> queue = new LinkedList<>(); //int형 queue 선언
queue.add(1); // queue에 값 1 추가
queue.add(2); // queue에 값 2 추가
queue.add(3); // queue에 값 3 추가
queue.add(4); // queue에 값 4 추가
queue.add(데이터)
출력 방향 <---------------------------< 입력 방향
1 <- 2 <- 3 <- 4
<---------------------------<
// 들어간 순서대로, 1번이 제일 먼저 들어가고 4번이 마지막으로 들어가게 됨
// 큐가 빌 때까지 데이터를 전부 뺌
queue.poll(); // queue에 첫번째 값을 반환하고 제거
queue.poll();
queue.poll();
queue.poll();
queue.poll()
출력 방향 <---------------------------< 입력 방향
<---------------------------<
1, 2, 3, 4
// 제일 첫 번째 있는 데이터부터 차례대로 나옴
2. 데이터는 하나씩 넣고 뺄 수 있음
: 큐 자료 구조는 데이터가 아무리 많아도 하나씩 데이터를 넣고 뺌, 한꺼번에 여러 개 뺄 수 없음
3. 두 개의 입출력 방향을 가지고 있음
: 큐 자료 구조는 데이터의 입력, 출력 방향이 다름, 같으면 큐 자료 구조라고 볼 수 없음
✍🏻 장점
- 자료를 먼저 넣은 순서대로 데이터를 꺼내서 처리 가능, 처리해야 할 작업이 여러 개일 경우 효율적인 처리 가능
: 큐의 가장 앞에는 가장 오래전에 삽인된 데이터가 위치하고 가장 뒤에서는 가장 최근에 삽인된 데이터가 위치
즉, 큐에 데이터를 삽입하는 순서와 삭제하는 순서가 동일하게 유지되어야 함
(프린터에서 인쇄 요청이 들어온 순서대로 처리하는 경우, 은행에서 대기 중인 고객 순서를 결정하는 경우) - 큐는 삽입과 삭제가 각각 양 끝에서 이루어지며 원소를 삭제하는 연산이 없으므로 다른 자료 구조에 비해 상대적으로 빠른 속도를 보임
: 중간에 있는 원소를 삭제하는 연산 없음 → 배열이나 다른 자료 구조와는 다른 모습 - 자바에서는 큐를 기본 자료 구조로 제공하기 때문에 별도의 라이브러리나 모듈을 설치할 필요없음
✍🏻 단점
- 큐에는 자료 구조의 가장 앞에서 데이터를 꺼내는 연산과 가장 뒤에서 데이터를 추가하는 연산만 가능하기 때문에 중간에 있는 데이터를 조회하거나 수정하는 연산에는 적합하지 읂음
- 크기 제한이 없어 메모리의 낭비가 발생할 수 있음 (자바에서 제공하는 큐 인터페이스의 경우)
: 크기 제한이 있는 큐를 구현할 때는, 이를 직접 구현하거나 기존의 Queue 인터페이스를 상속받아 크기 제한을 추가한 클래스를 구현해야 함 - iterator() 메서드가 지원되지 않음 (Java에서 제공하는 Queue 인터페이스의 경우)
: Queue 인터페이스가 FIFO(First-In-First-Out) 구조를 갖기 때문에 큐의 데이터를 순회할 때는 peek() 메서드와 poll() 메서드를 사용하여 각각의 데이터를 차례대로 가져와야 함 - remove(Object o) 메서드의 동작이 불명확 (Java에서 제공하는 Queue 인터페이스의 경우)
: Queue 인터페이스에서 제공하는 remove(Object o) 메서드는 해당 객체를 큐에서 삭제하지만 이 메서드는 큐가 중복된 객체를 허용하는 경우, 어떤 객체가 삭제되는지 명확하지 않음 따라서 이 메서드를 사용할 때는 poll() 메서드를 사용하여 원하는 객체를 삭제해야 함
사실 이해 자체는 그렇게 어렵지 않았다. 막상 코드로 구현하려니 앞에 내용들과 뒤죽박죽 섞여서 애를 먹었다. 그래도 스택은 스스로 해냈는데 큐를 구현하는 건 아직 많이 헷갈렸다. 좀 더 코드로 풀어보고 익숙해지도록 연습을 많이 해야할 것 같다. 처음에는 머리가 터질 것 같았는데 그래도 하나씩 구현을 해보고 코플릿 문제도 반복해서 보니까 오히려 재밌다. 역시 계속 반복하고 친해지는 게 답인 것 같다. 내일도 파이팅👍
'SEB_BE_45 > 공부 정리' 카테고리의 다른 글
| [Section2] 06. 자료구조와 알고리즘 3 / 20230517 (0) | 2023.05.18 |
|---|---|
| [Section2] 04. 자료구조와 알고리즘 - Graph, Tree 1 / 20230515 (1) | 2023.05.16 |
| [Section2] 02. 자료구조와 알고리즘 기초 - 재귀 / 20230511 (0) | 2023.05.11 |
| [Section2] 01. 자료구조와 알고리즘 기초 - 재귀 (0) | 2023.05.10 |
| [SEB BE] Section 1 회고 / 20230509 (0) | 2023.05.09 |






